Text Classification in Data Analysis Platform DEEP
About DEEP
The DEEP is an online platform for secondary data analysis, supporting analysts from different parts of the world to address scope and scale of crisis happening around. The data analysis focuses on the living status of affected people and the underlying factors that affect people. Also, the platform helps to know the existing information gaps regarding sectors, geographical areas and affected groups.
Requirement for Natural Language Processing
There are a lots of documents and reports being added in DEEP everyday and there are many analysts who are tagging the documents and texts into different sectors and categories. This is a time consuming process and something that can be automated. This is where Natural Language Processing comes in as a mechanism for automated text classification which is really going to help the analysts.
Naive Bayes Classifier
It is one of the most simple classifiers in use. Although simple, we chose it for the following reasons:
- It is very simple, easy to implement and fast to train.
- It works well even with small training data. And we had enough of data.
- It can not only do binary classification, but also multi-class classification, which is what we require. There are around 12 classes we need to classify texts over.
Dataset and Pre-processing
The source for our training data is the DEEP database where information collected and added by analysts are stored. Since the database consisted of a bit complex format for storing information, we needed to pre-process the data. A csv sample of data extracted:
count,onedim_j,twodim_j,reliability,severity,demo_groups_j,specific_needs_j,aff_groups_j,geo_j,info_date,excerpt,has_image,lead_text,lead_id,lead_url,event
1,"{""Population Profile"": [""Demographic Profile""]}",null,Usually,Situation of Concern,"[""Children (5 to 11 years old)""]",null,"[""Affected""]",null,2016-11-15,"894,057 children are among the 2.1 million affected people",True,None,4,http://reliefweb.int/sites/reliefweb.int/files/resources/SITREP%2014%20-%20HAITI%20%2821%20OCT%202016%29_0.pdf,Test Event
2,null,"[{""sector"": ""Nutrition"", ""subsectors"": [""Breastfeeding""], ""pillar"": ""Humanitarian conditions"", ""subpillar"": ""2nd level outcome""}]",Usually,Severe Conditions,"[""Infants/toddlers (< 5 years old)""]",null,"[""Affected""]",null,2016-11-15,"112,500 children under five are at risk of acute malnutrition.",True,None,4,http://reliefweb.int/sites/reliefweb.int/files/resources/SITREP%2014%20-%20HAITI%20%2821%20OCT%202016%29_0.pdf,Test Event
We just required two things from the data: excerpt(text) and sector(label). The following is the code used to process the data into list of tuple containing (text, label).
import json
import pandas as pd
import googletrans
import langdetect
def process_deep_entries_data(csv_file_path):
"""
Take in a csv file consisting of folloing columns:
'onedim_j', 'twodim_j', 'reliability', 'severity', 'demo_groups_j',
'specific_needs_j', 'aff_groups_j', 'geo_j', 'info_date', 'excerpt',
'has_image', 'lead_text', 'lead_id', 'lead_url', 'event'
Process it(remove stop words, translate language,...)
And return list of tuples: [(text, label)...]
"""
df = pd.read_csv(csv_file_path, header=0)
# Convert json string columns to json
df[df.filter(like="_j").columns] = df.filter(like="_j").applymap(
lambda x: json.loads(x)
)
# Change column names
for v in df.filter(like="_j"):
df = df.rename(columns={v: '_'.join(v.split('_')[:-1])})
# filter texts only if langid english
return get_sector_excerpt(df)
def get_sector_excerpt(df, translate=False):
"""Return list of tuples with sector and excerpt -> [(excerpt, sector)...]
@df : DataFrame
"""
if translate:
translator = googletrans.Translator()
lst = []
for v in df[df['twodim'].notnull()][['twodim', 'excerpt']].iterrows():
for k in v[1].twodim:
excerpt = v[1].excerpt
if type(excerpt) != str or not excerpt.strip():
continue
excerpt = re.sub('[\r\n\t]', ' ', v[1].excerpt)
if translate:
try:
lang = langdetect.detect(excerpt)
except Exception:
continue
if lang != 'en':
excerpt = translator.translate(excerpt).text
lst.append((excerpt, k['sector']))
return lst
The above functions extract the data from database into structure that we require for training. Only translations and newlines have been removed in this step because we don’t want to lose too much of information yet. For further processing, we have the following functions:
from nltk.corpus import wordnet as wn
def remove_punc_and_nums(input):
"""remove punctuations and replace numbers with NN"""
punc = string.punctuation
punc = punc.replace('-', '')
transtable = str.maketrans("", "", punc)
punc_removed = input.translate(transtable)
return re.sub('[0-9]+', 'NN', punc_removed)
def rm_stop_words_txt(txt, swords=nltk.corpus.stopwords.words('english')):
""" Remove stop words from given text """
return ' '.join(
[token for token in str(txt).split(' ')
if token.lower() not in swords]
)
nltk_wordnet_tag_map = {
'NN': wn.NOUN,
'NNS': wn.NOUN,
'VBP': wn.VERB,
'VBG': wn.VERB,
'JJ': wn.ADJ,
}
def lemmatize(text, lemmatizer=WordNetLemmatizer()):
splitted = text if type(text) == list else str(text).split()
splitted = [str(x).lower() for x in splitted]
tagged = nltk.pos_tag(splitted)
lemmatized = []
for word, tag in tagged:
wnet_tag = nltk_wordnet_tag_map.get(tag)
if wnet_tag:
lemmatized.append(lemmatizer.lemmatize(word, wnet_tag))
else:
lemmatized.append(word)
return ' '.join(lemmatized)
Stop words, lemmatization, words tags have been used from nltk, which is a nice python library to play with NLP. The complete processing, before feeding the texts to our classifier goes like this:
def preprocess(inp, ignore_numbers=False):
"""Preprocess the input string"""
# compose the processing functions into a single function(order is numbered)
processor = compose(
' '.join, # 7. Join words wih spaces
str.split, # 6. Split the input(just in case)
lemmatize, # 5. Lemmatize for consistency
rm_stop_words_txt, # 4. Remove stop words if any
remove_punc_and_nums, # 3. Remove punctuations and numbers
str.lower, # 2. Then, convert to lowercase
str # 1. convert to string(just in case input is not string)
)
processed = processor(inp)
if ignore_numbers:
return processed.replace('nn', '') # because remove_punc_and_nums replaces numbers with NN
return processed
def compose(*functions):
"""This just composes the input functions"""
from functools import reduce
def compose2(f1, f2):
"""Compose two functions"""
return lambda *args: f1(f2(*args))
return reduce(compose2, functions)
Using NLTK’s Naive Bayes Classifier
NLTK provides a very easy to use Naive Bayes Classifier. The input to the classifier is a list of tuples each consisting of text features and label. Text features in our case(and in most of the cases) is a dict containing unique words and their counts. The simplifed code is:
import random
import nltk
def get_features(processed_text):
return {x: 1 for x in processed_text.split()}
def create_classifier(labeled_data):
""" labeled_data is [(text, label), ...] """
labeled_features = [(get_features(x), y) for x, y in labeled_data]
random.shuffle(labeled_features)
test, train = labeled_features[500:], labeled_features[:500]
classifier = nltk.NaiveBayesClassifier.train(train)
return classifier # now use as classifier.classify(<text>)
Although, this is a very easy way to create a classifier, creating a model for around 10,000 training data took quite a lot of memory and cpu consumption, and ran for around 15-20 minutes in a moderate machine. And the worst part was the accuracy being very small(just around 52%) than what we had hoped. The following graph shows accuracy values for different data sizes.
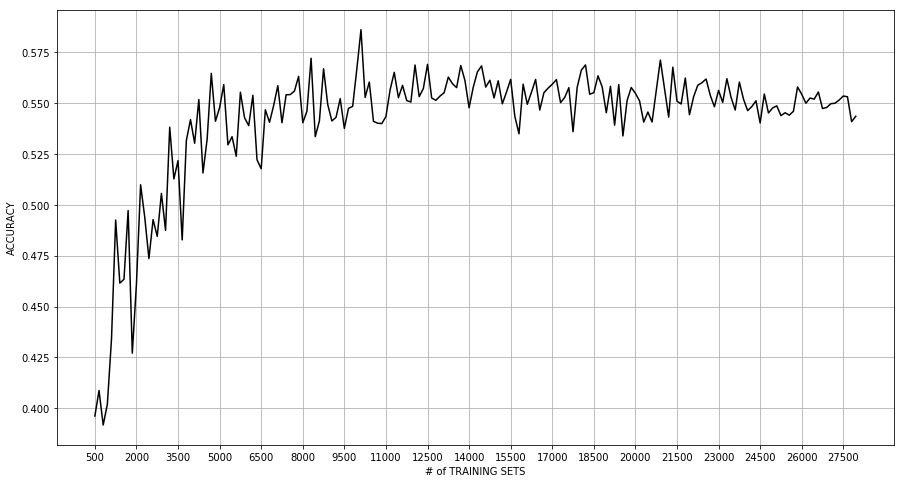
Switching to scikit-learn’s Naive Bayes Classifier
Scikit-Learn is also one of the most popular and excellent libraries for machine learning. Using Naive Bayes Classifier is not as straightforward as using that of NLTK, but it’s just a couple of lines of code. Simplified code for the classifier is shown below.
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.naive_bayes import MultinomialNB
from sklearn.pipeline import Pipeline
import numpy as np
def create_classifier(training_data):
"""training_data is list of tuples: [(text, label), ...]"""
classifier = Pipeline([
('vect', CountVectorizer(ngram_range=(1, 2))),
('tfidf', TfidfTransformer(use_idf=False)),
('clf', MultinomialNB(alpha=0.01, fit_prior=False))
])
train, target = zip(*train_labeled)
classifier = classifier.fit(train, target)
return classifier
def calculate_accuracy(classifier, test_data):
"""test_data: [(text, label), ...]"""
test, test_target = zip(*test_data)
predicted = classifier.predict(test)
return np.mean(predicted == test_target)
But to our astonishment, the training speed was insanely fast, compared to the last one. It just took about 1 minute to train. And the best part was the accuracy coming to be higher than that from NLTK. The model was 68% accurate.
With some tuning and refining, we got it upto 71%. This accuracy is not a very good one. But it’s not bad either. And we think the model is usable right away. The following graph shows accuracy values for different data sizes.
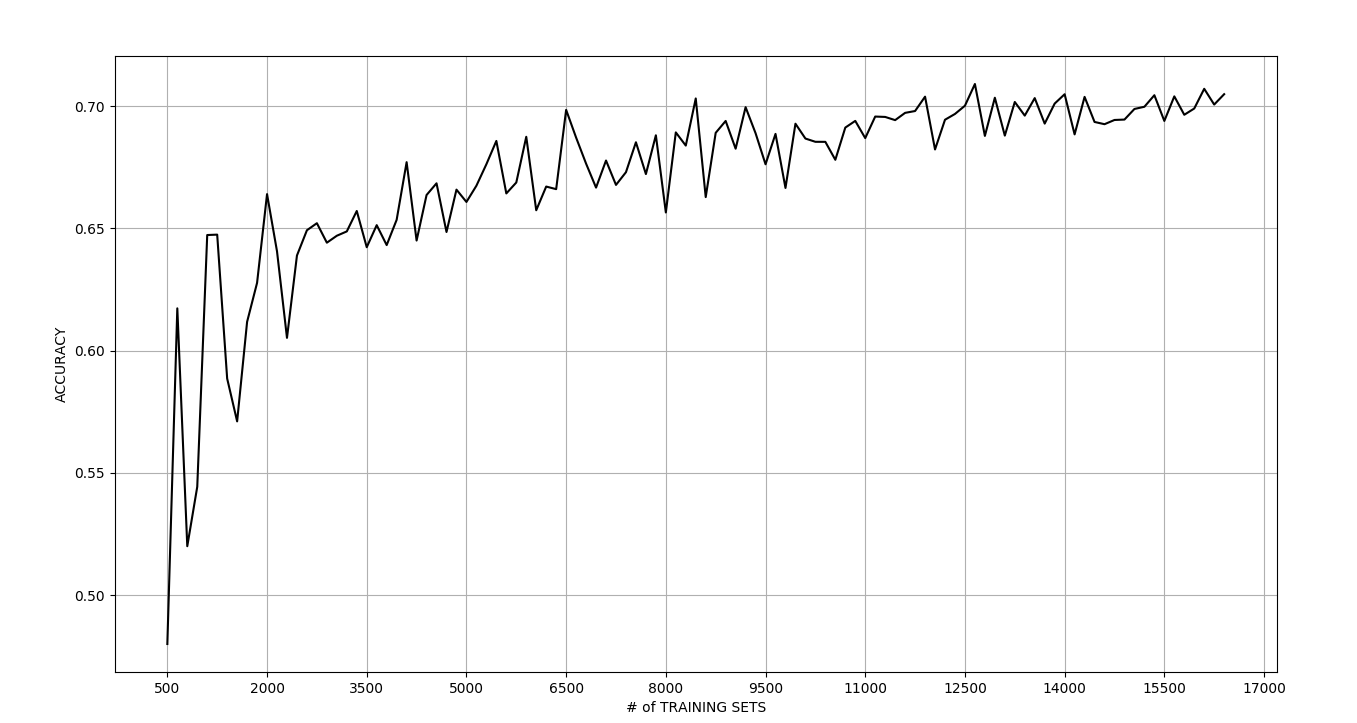
Now with even larger dataset
As we had been working on the models and experimenting on them, more and more data were being added to DEEP. We have collected the new data and now we are with a dataset double the size of what we had previously. There are nearly 40,000 rows.
However, upon training the model with the dataset, the accuracy decreased instead of increasing. We just got around 65% accurate results. Generally, larger dataset means better accuracy, which was not true in our case.
Analyzing the Results
The initial accuracy was the worst(with nltk), which increased significantly with the second model(with sklearn) and with more dataset, the accuracy decreased slightly. Carefully looking at the confusion matrices and the dataset samples, we found the following reasons for overall accuracy not being so good and the accuracy degrading with increase in dataset:
- There are 12 classes that we have to classify texts over. Some of them were similar with each other. This overlapping of the classes resulted in a lot of the test predictions to fail.
- The analysts are allowed to tag multiple classes for a text. Thus, the dataset has multiple labels for same text as well. But, the classifier model predicts only one class for a text.
- We have done enough preprocessing and text translation for non-english texts as well. So maybe, Naive Bayes classifier model is not suiting our purpose well.
Road Ahead
There’s always a room for enhancemend no matter how good things are. With our moderately accurate text classifier, we have plenty of room for improvement and a lot of things to try, which are summarized below:
- First thing, we have a problem with our dataset: multiple labels assigned to a single text. We should either modify our classifier to predict muitiple classes or limit our dataset to have single label for a text.
- There are a lot of advanced classifier models, one of them being SVM which is a binary classifier. We can use “one vs. all” classification method to fit our purpose for multi-class classification.
- Maybe, we can merge similar labels into one label so that we have non overalapping classes.